xv6最难的实验之一,和页表打交道真的很痛苦呢XD
Table of contents
Open Table of contents
Speed up system calls
正常情况下,用户程序系统调用需要用ecall指令陷入内核usertrap()函数中,这样的上下文和页表切换都十分消耗时间。而我们不希望一些简单的read-only系统调用,例如getpid,gettimeofday等需要完成这一套系统调用流程.所以我们可以重新设计这些简单的read-only系统调用让他避免陷入内核(在linux中为vdso)
Some operating systems (e.g., Linux) speed up certain system calls by sharing data in a read-only region between userspace and the kernel. This eliminates the need for kernel crossings when performing these system calls.
xv6希望我们在用户地址空间的最上方分配一页专门用于”sharing data between userspace and the kernel”的USYSCALL页,我们可以为我们需要share的data分配一个专门的结构体usyscall储存在USYSCALL页中.所以我们只需要为每一个进程维护一个USYSCALL -> Kernel Data的映射即可
#define USYSCALL (TRAPFRAME - PGSIZE)
struct usyscall {
int pid; // Process ID
};
首先我们在进程初始化页表时为其添加一个虚拟地址映射,将USYSCALL映射到内核物理地址中的某一页
// proc.c
extern struct usyscall *usys;
...
pagetable_t
proc_pagetable(struct proc *p)
{
...
// map the usys page just below the trapframe page
if(mappages(pagetable, USYSCALL, PGSIZE,
(uint64)usys, PTE_R | PTE_U ) < 0){
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmunmap(pagetable, TRAPFRAME, 1, 0);
uvmfree(pagetable, 0);
return 0;
}
...
}
这样每个用户进程访问虚拟地址USYSCALL时,都会被映射到内核中的某一页上,我们只需要在内核初始化时分配这些页并且在运行时修改这些页,用户进程就可以从虚拟地址USYSCALL中读取到内核的信息而不用陷入内核中
// vm.c
struct usyscall * usys;
// kvmmake()
// map syscall page
usys = (struct usyscall *)kalloc();
kvmmap(kpgtbl , USYSCALL,(uint64)usys,PGSIZE,PTE_R | PTE_W);
...
然后在内核运行时修改usys即可,这里是修改进程运行的pid,我们到调度器中添加修改pid的逻辑:
//proc.c scheduler()
...
p->state = RUNNING;
c->proc = p;
struct usyscall sys = {
p->pid
};
*usys = sys;
swtch(&c->context, &p->context);
...
(在多核心的情况下应该需要维护每个CPU上进程的pid) 最后,在每个进程结束时我们需要把之前映射的页表项给销毁.
//proc.c proc_freepagetable()
void
proc_freepagetable(pagetable_t pagetable, uint64 sz)
{
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmunmap(pagetable, TRAPFRAME, 1, 0);
uvmunmap(pagetable, USYSCALL, 1, 0);
uvmfree(pagetable, sz);
}
在添加了一个syscall后,继续添加诸如gettimeofday等syscall就会简单很多,比如每一秒都更新usys中的time字段,这样在获得时间时也不需要陷入内核了.
实际上,这道题还可以在每个进程创建时单独为他分配一个页,里面储存一个其pid,或者直接把USYSCALL映射到其pid字段的地址上,这样解题会简单很多,但这要为每一个进程额外分配一页,可扩展性不好,不是很符合vdso的思想.
Print a page table (easy)
遍历打印页表即可
// vm.c
void
vmprint(pagetable_t pagetable) {
// your code here
printf("page table %p\n", pagetable);
tbprint(pagetable, 1 , 0);
}
void
tbprint(pagetable_t pagetable , int depth , int pre_va){
for(int i = 0 ; i < 512 ; i++){
uint64 pte = pagetable[i];
if(pte & PTE_V){
for(int j = 0 ; j < depth ; j++){
printf(" ..");
}
// calulate the va
uint64 va = i << PXSHIFT(3-depth) | pre_va;
uint64 pa = PTE2PA(pte);
printf("%p: %p %p\n", (void *)va , (void*)pte , (void*)pa);
if(!PTE_LEAF(pte)){
tbprint((pagetable_t)PTE2PA(pte), depth + 1 , va);
}
}
}
}
Use superpages (Hard)
非常重量级的实验,涉及到页表debug非常折磨,本身需要的代码量也非常大,很容易出错,出错很难察觉.但是做完确实对页表的理解更深入了().
首先实现巨型页的分配,为了分配巨型页,我们需要维护一个巨型页的空闲列表superfreelist,并且添加巨型页的分配和销毁函数,这一段比较简单,照着kalloc和kfree编写即可
// riscv.h
#define SUPERNUM 10
#define SUPERSIZE (SUPERPGSIZE * SUPERNUM)
// kalloc.c
struct {
struct spinlock lock;
struct run *freelist;
struct run *superfreelist;
} kmem;
void
freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
for(; p + PGSIZE <= (char*)(pa_end - SUPERSIZE); p += PGSIZE)
kfree(p);
p = (char*)SUPERPGROUNDUP((uint64)p);
for(; p + SUPERPGSIZE <= (char*)pa_end; p += SUPERPGSIZE)
superfree(p);
}
void *
superalloc(void)
{
struct run * r;
acquire(&kmem.lock);
r = kmem.superfreelist;
if(r)
kmem.superfreelist = r->next;
release(&kmem.lock);
if(r)
memset((char*)r, 5, SUPERPGSIZE);
return (void*)r;
}
void superfree(void * pa)
{
struct run *r;
if(((uint64)pa % SUPERPGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("superfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, SUPERPGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.superfreelist;
kmem.superfreelist = r;
release(&kmem.lock);
}
不要忘了在defs.h中添加相关函数的声明
// defs.h
void * superalloc(void);
void superfree(void *);
然后就要开始分配页表了,首先我们来到进程申请堆空间的入口,我们希望在能分配巨型页时就分配巨型页,但是这面临一个问题,用户申请的堆空间不一定是对齐的,我们分配巨型页时还需要用小页来填充巨型页不对齐的部分.
// proc.c
int growproc(int n) {
uint64 sz;
struct proc *p = myproc();
sz = p->sz;
uint64 oldsz = sz;
uint64 newsz = SUPERPGROUNDUP(sz);
int spnum = n / SUPERPGSIZE;
if (n > 0) {
if (spnum > 0 && spnum < 8) { // 太多了就不分配了
// 填充间隙
if (newsz > sz) {
if ((sz = uvmalloc(p->pagetable, sz, newsz, PTE_W | PTE_R)) == 0) {
return -1;
}
}
p->sz = sz;
// 分配巨页
if ((sz = superuvmalloc(p->pagetable, sz, sz + spnum * SUPERPGSIZE,
PTE_W)) == 0) {
return -1;
}
p->sz = sz;
} else
// 如果没分配巨页,正常分配普通页
// 如果分配过了巨页,sz指向最后一个对齐的巨页顶,这里还需要分配额外的填充页
if ((sz = uvmalloc(p->pagetable, sz, oldsz + n, PTE_W)) == 0) {
return -1;
}
} else if (n < 0) {
sz = uvmdealloc(p->pagetable, sz, sz + n);
}
p->sz = sz;
return 0;
}
然后我们再来看巨页分配函数superuvmalloc,我们仿照uvmalloc,为每一个虚拟地址分配一个巨页并且建立虚拟地址到物理地址的映射
//vm.c
uint64
superuvmalloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz, int xperm){
char *mem;
uint64 a;
int sz;
if(newsz < oldsz)
return oldsz;
oldsz = SUPERPGROUNDUP(oldsz);
for(a = oldsz; a < newsz; a += sz){
sz = SUPERPGSIZE;
mem = superalloc();
if(mem == 0){
uvmdealloc(pagetable, a, oldsz);
return 0;
}
if(supermappages(pagetable, a, sz,(uint64)mem, PTE_U|xperm) != 0){
superfree(mem);
uvmdealloc(pagetable, a, oldsz);
return 0;
}
}
return newsz;
}
接着是supermappages,用来把一个虚拟地址映射到一个具体的大页上,这里我们定义了一个特殊的SP位用于标注这个页是SUPER页
//riscv.h
#define PTE_SP (1L << 9) // super page
//vm.c
int
supermappages(pagetable_t pagetable,uint64 va , uint64 size,uint64 pa,int perm){
uint64 a, last;
pte_t *pte;
if((va % SUPERPGSIZE) != 0)
panic("supermappages: va not aligned");
if((size % SUPERPGSIZE) != 0)
panic("supermappages: size not aligned");
if(size == 0)
panic("supermappages: size");
a = va;
last = va + size - SUPERPGSIZE;
for(;;){
if((pte = superwalk(pagetable, a, 1)) == 0)
return -1;
if(*pte & PTE_V)
panic("supermappages: remap");
*pte = PA2PTE(pa) | perm | PTE_V | PTE_SP;
if(a == last)
break;
a += SUPERPGSIZE;
pa += SUPERPGSIZE;
}
return 0;
}
superwalk用于根据虚拟地址找出/分配巨页的pte
//vm.c
// walk a super page in level 1
pte_t *
superwalk(pagetable_t pagetable, uint64 va, int alloc)
{
if(va >= MAXVA)
panic("superwalk");
pte_t *pte = &pagetable[PX(2, va)];
if(*pte & PTE_V ) {
pagetable = (pagetable_t)PTE2PA(*pte);
} else {
if(!alloc || (pagetable = (pde_t*)kalloc()) == 0)
return 0;
memset(pagetable, 0,PGSIZE);
*pte = PA2PTE(pagetable) | PTE_V ;
}
return &pagetable[PX(1, va)];
}
xv6已经帮我们修改了walk来识别巨型页,只要walk发现某个pte不是叶子节点(被分配了其他标志),那就立刻返回.
//riscv.h
#define PTE_LEAF(pte) (((pte) & PTE_R) | ((pte) & PTE_W) | ((pte) & PTE_X))
//vm.c
pte_t *
walk(pagetable_t pagetable, uint64 va, int alloc)
{
...
#ifdef LAB_PGTBL
if(PTE_LEAF(*pte)) {
return pte;
}
#endif
...
}
至此,我们便完成了一个巨页分配的所有流程,接下来我们还要实现对巨页的释放和复制 uvmunmap需要释放虚拟地址va开始的npages页页表,我们需要在里面添加识别巨页的逻辑
// vm.c
void
uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)
{
uint64 a;
pte_t *pte;
int sz;
if((va % PGSIZE) != 0)
panic("uvmunmap: not aligned");
for(a = va; a < va + npages*PGSIZE; a += sz){
if((pte = walk(pagetable, a, 0)) == 0)
panic("uvmunmap: walk");
if((*pte & PTE_V) == 0) {
printf("va=%ld pte=%ld\n", a, *pte);
panic("uvmunmap: not mapped");
}
if(PTE_FLAGS(*pte) == PTE_V)
panic("uvmunmap: not a leaf");
if(*pte & PTE_SP){
// 如果是巨页就释放SUPERSIZE大小的内存
sz = SUPERPGSIZE;
if(do_free){
superfree((void*)PTE2PA(*pte));
}
} else{
sz = PGSIZE;
if(do_free){
uint64 pa = PTE2PA(*pte);
kfree((void*)pa);
}
}
// 把leaf的pte归零
*pte = 0;
}
}
(我们不需要修改uvmdealloc,因为uvmdelloc调用的就是uvmunmap,他只是一个更好用的包装函数) 接下来是uvmcopy,我们需要遍历父进程的虚拟地址,把所有页都copy过去
// vm.c
int uvmcopy(pagetable_t old, pagetable_t new, uint64 sz) {
pte_t *pte;
uint64 pa, i;
uint flags;
char *mem;
int szinc;
for (i = 0; i < sz; i += szinc) {
szinc = PGSIZE;
szinc = PGSIZE;
if ((pte = walk(old, i, 0)) == 0) panic("uvmcopy: pte should exist");
if ((*pte & PTE_V) == 0) panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
if (flags & PTE_SP) {
szinc = SUPERPGSIZE;
if ((mem = superalloc()) == 0) goto err;
memmove(mem, (char *)pa, SUPERPGSIZE);
if (supermappages(new, i, SUPERPGSIZE, (uint64)mem, flags) != 0) {
superfree(mem);
goto err;
}
} else {
if ((mem = kalloc()) == 0) goto err;
memmove(mem, (char *)pa, PGSIZE);
if (mappages(new, i, PGSIZE, (uint64)mem, flags) != 0) {
kfree(mem);
goto err;
}
}
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}
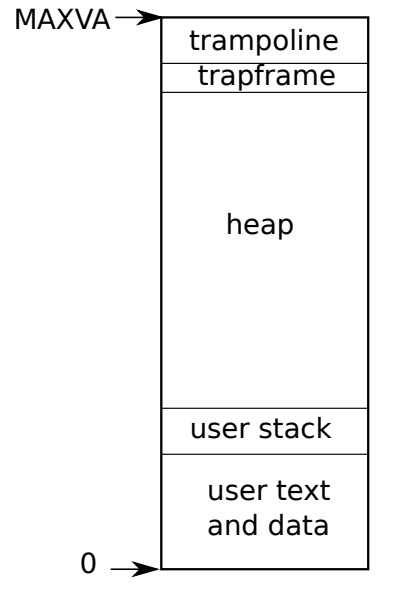
为什么可以从0开始遍历虚拟地址呢?这就不得不提到xv6进程的虚拟地址空间了
user text ann data和user stack段都是在exec时就被映射的区域,heap没被分配,但是在用户运行时向上增长,而最上面的trampoline被映射在固定的物理内存,无需修改,trapframe则是由内核来接管分配,复制与清除,所以,uvmcopy和uvmfree都是从va = 0开始遍历整个进程的虚拟内存
总结
这个实验还是非常有意思的,虽然花了我很多很多时间debug,最终结果也算是差强人意吧,整个xv6的结构非常美观,非常适合钻研()